本文描述了如何通过 Python Flask REST API 向外界暴露机器学习模型。

Flask 正如其官方网站所述,充满乐趣且易于安装。确实,这个 Python 的微框架提供了一种使用 REST 端点注释 Python 函数的有效方式。目前我使用 Flask 发布机器学习模型 API,以供第三方业务应用程序访问。
此示例基于 XGBoost。
为了更佳的代码维护性,我建议使用一个单独的 Jupyter notebook 发布机器学习模型 API。导入 Flask 和 Flask CORS 模块:
1
2
3
4
5
from flask import Flask, jsonify, request
from flask_cors import CORS, cross_origin
import pickle
import pandas as pd
该模型使用皮马印第安人糖尿病数据集(Pima Indians Diabetes Database)训练。CSV 数据可以从这儿下载。要构建一个 Pandas 数据帧类型的变量来作为模型预测函数的输入,我们需要定义一个包含数据集的列名的数组:
1
2
# 获取请求头中的 payload
headers = ['times_pregnant', 'glucose', 'blood_pressure', 'skin_fold_thick', 'serum_insuling', 'mass_index', 'diabetes_pedigree', 'age']
使用 Pickle 加载预训练模型:
1
2
3
# 使用 Pickle 加载预训练模型
with open(f'diabetes-model.pkl', 'rb') as f:
model = pickle.load(f)
测试运行并检查模型是否运行良好是个好习惯。首先使用一个列名数组和一个数据数组(使用不在训练或测试数据集中的新数据)来构造数据帧。然后调用两个函数 —— model.predict 和 model.predict_proba 中的任意一个。我通常更喜欢 model.predict_proba,它返回预测结果为 0 或为 1 的概率,这有助于解释某个范围内(例如 0.25 到 0.75)的结果。最后使用一个示例 payload 构建 Pandas 数据帧,然后执行模型预测:
1
2
3
4
5
6
7
8
9
10
11
# 用数据帧测试模型
input_variables = pd.DataFrame([[1, 106, 70, 28, 135, 34.2, 0.142, 22]],
columns=headers,
dtype=float,
index=['input'])
# 获取模型的预测结果
prediction = model.predict(input_variables)
print("Prediction: ", prediction)
prediction_proba = model.predict_proba(input_variables)
print("Probabilities: ", prediction_proba)
以下是 Flask API 的写法。确保启用 CORS,否则来自其他主机的 API 调用将无法成功。在要通过 REST API 暴露的函数前加上注释,并提供端点的名称和支持的 REST 方法(本例中为 POST)。从请求中获取 payload 数据,接着是构造 Pandas 数据帧并执行模型 predict_proba 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
app = Flask(__name__)
CORS(app)
@app.route("/katana-ml/api/v1.0/diabetes", methods=['POST'])
def predict():
payload = request.json['data']
values = [float(i) for i in payload.split(',')]
input_variables = pd.DataFrame([values],
columns=headers,
dtype=float,
index=['input'])
# 获取模型的预测结果
prediction_proba = model.predict_proba(input_variables)
prediction = (prediction_proba[0])[1]
ret = '{"prediction":' + str(float(prediction)) + '}'
return ret
# 运行 REST 接口,port=5000 用于直接测试
if __name__ == "__main__":
app.run(debug=False, host='0.0.0.0', port=5000)
函数结果被构造成 JSON 字符串并作为响应返回。我在 Docker 容器中运行 Flask,这就是为什么使用 0.0.0.0 作为它运行的主机 IP。端口 5000 被映射为外部端口,可以允许来自外部的调用。
虽然直接在 Jupyter notebook 中启动 Flask 接口也是可行的,但我还是建议将其转换为 Python 脚本并作为服务从命令行运行。使用 Jupyter nbconvert 命令将其转换为 Python 脚本:
jupyter nbconvert — to python diabetes_redsamurai_endpoint_db.ipynb
Flask 程序可以利用 PM2 进程管理器从后台启动。这种方式可以将端点作为服务启动,并且能启用多个运行在不同端口的进程(用于负载均衡)。PM2 启动命令:
pm2 start diabetes_redsamurai_endpoint_db.py

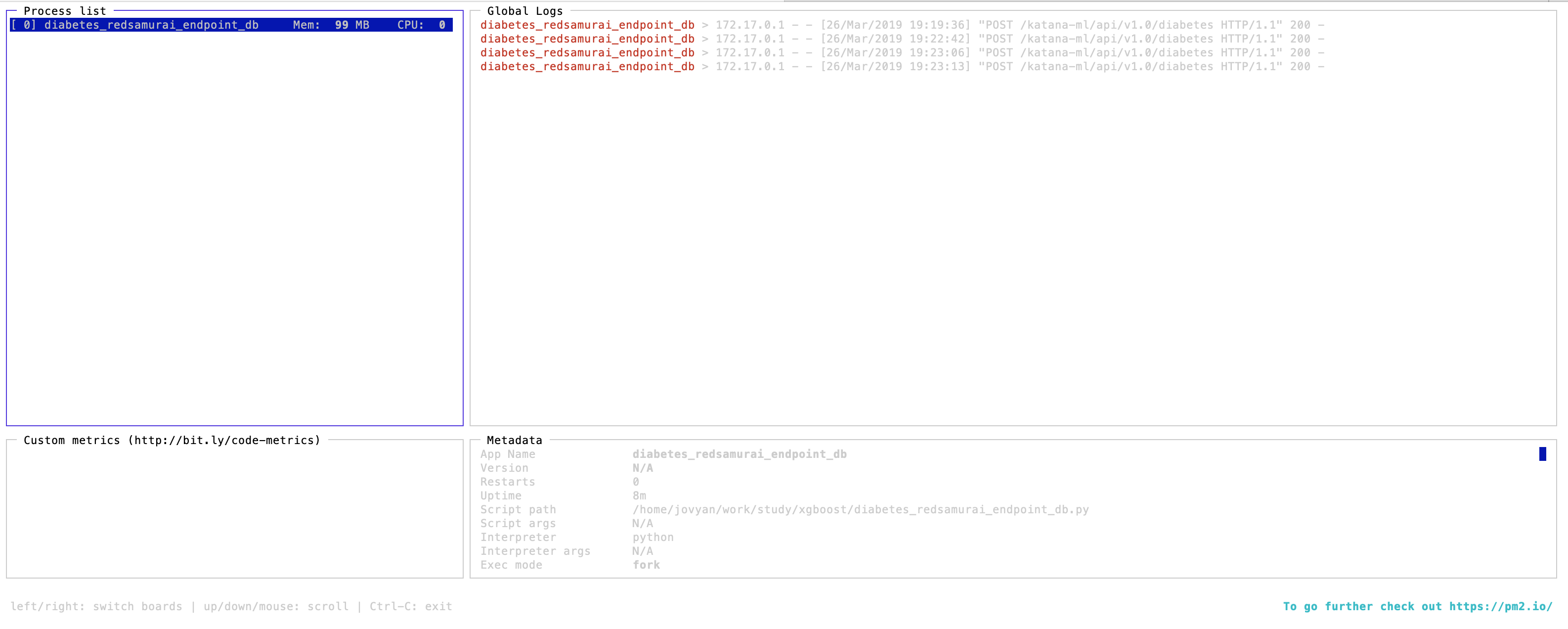
pm2 monit 能够展示运行中的进程的信息:
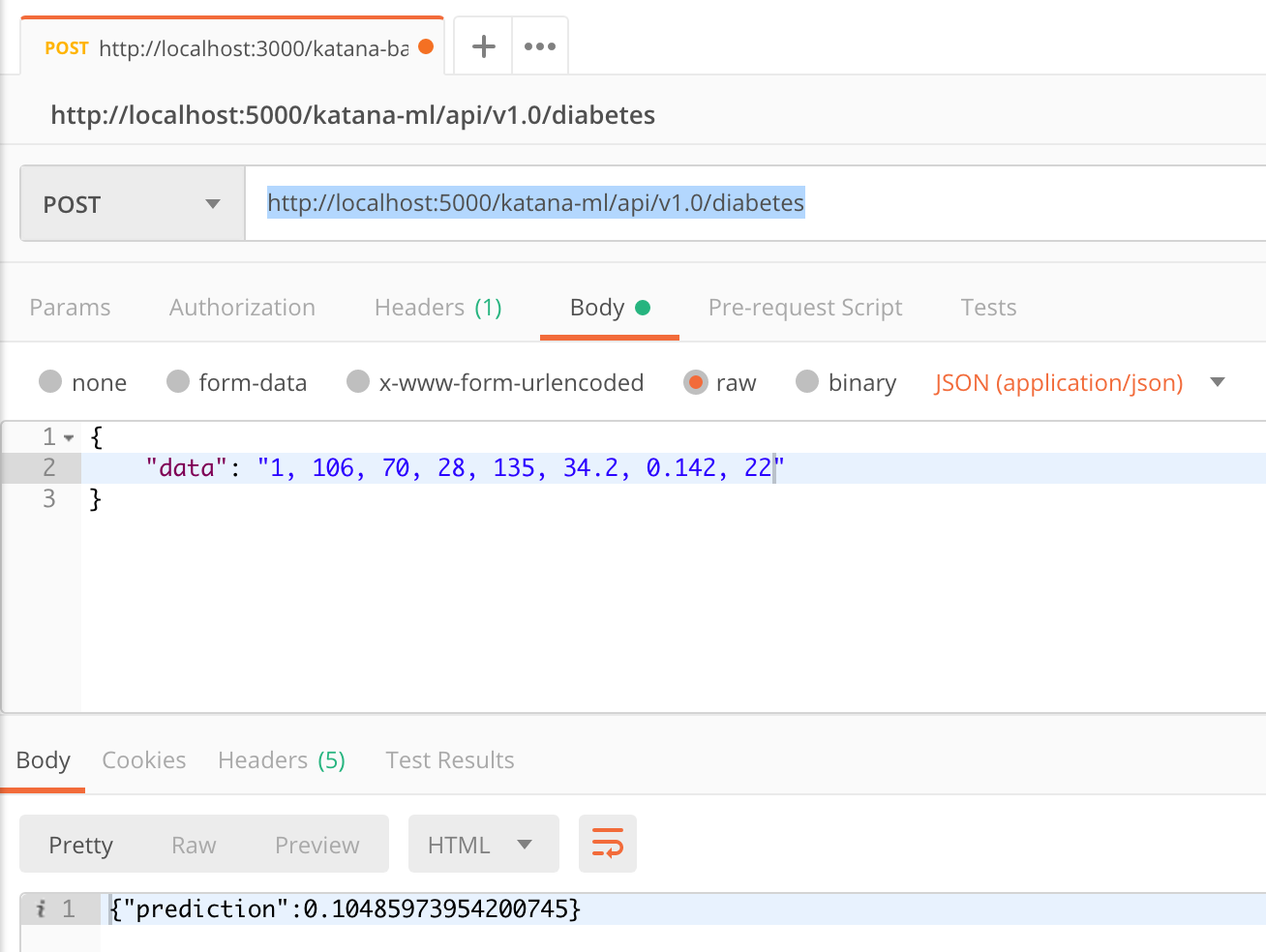
用 Postman 调用 Flask 提供的机器学习分类模型 REST API: